这篇博客是这一季度分布式存储研究论文研读的第二篇,主要记录的是论文Bigtable: A Distributed Storage System for Structured Data的研读情况。论文发表于OSDI 2006。
首先和论文无关,还是想分享一下来自Malte Schwarzkopf博士毕业论文Operating System support for warehouse-scale computing的一张Google基础服务架构图:
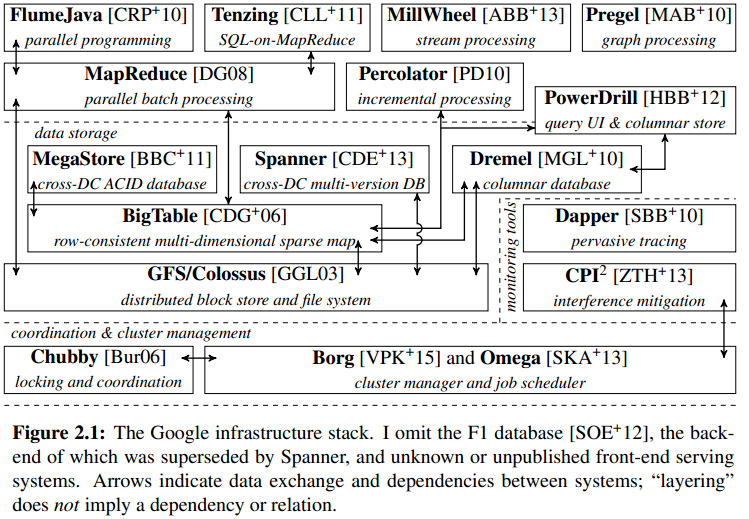
GFS和Bigtable都在其中,关系一目了然。
Data Model
Bigtable从本质上来讲应该类似于一种NoSQL数据库,同时又提供了普通的数据库所没有的接口。它的数据模型如下:
(row:string, column:string, time:int64) -> string
之后的一些NoSQL数据库如Cassandra,HBase等均有类似结构。结构中有以下几个组成部分:
- Row:可以看作每条数据是一行,对一行数据的读写操作是原子的。Bigtable会对row key进行字典序排列,尽管每张表的行范围分区随机,但设计良好的row key就能使相关数据相邻连续排列。读取时也只需要访问少数几台机器。
- Column:column key会被组织成column family,语法是column:qualifier。column family中几个key的取值类型一般相同,设计希望column family是预先设计好的,比较固定,且数量不多(但column的数量不限)。column family是访问控制的最小单位。
- Timestamp:时间戳最重要的功能是记录同一个值的不同版本。同时也能针对column family定义管理机制:只保留多久版本的记录,或保留最近几个版本。
API
Bigtable提供了一系列API供用户进行数据操作。有几个要点:
- 允许使用正则匹配列名,对匹配结果加以限制。
- 支持单行的事务。不支持跨行事务。
- Integer数据可用作计数器。
- 支持在服务器地址空间执行客户端提供的脚本。
支持脚本,但脚本不能写回Bigtable是什么意思?脚本不能写入数据,但能进行数据转换,数据过滤,数据汇总等“查询”类操作。
Bigtable的一大特点就是支持配合MapReduce使用。
Building Blocks
Bigtable作为比较上层的应用,依赖于一系列Google产品。
首先它的数据和日志文件是存储在GFS上的。
其次,它存储数据的数据结构是Google SSTable,这种数据结构将数据分为小块(64KB),并作索引。方便查找和映射到内存空间。
Bigtable还依赖于分布式锁服务:Chubby。Chubby具有较高的可用性,通常会维持5个分片并选举一个master。使用Paxos算法来保证分片一致性。Chubby提供一个由目录和文件组成的命名空间(namespace),每个目录或文件都可以作为锁,保证读写一个文件是原子操作。使用Chubby,Bigtable可以:
- 保证只有一个master节点(Bigtabled的master节点,可继续看下一章);
- 存储Bigtable数据的bootstrap位置;
- 存储Bigtable的Schema信息;
- 存储Bigtable的access control列表。
Implementation
Bigtable系统由三大部分组成:
- 一个所有客户端连接的library。
- master服务器负责分配分片到分片服务器,探测新加入和过期的分片服务器,均衡分片服务器负载,做GFS文件的垃圾回收,以及处理schema变动。
- 分片服务器管理一系列分片,处理分片的读写请求,数据都不会经过master节点。同时分片服务器也会对过大的分片进行切片。最终的分片大小大概在100-200MB左右,符合GFS的存储特点。
Table Location
下图是Bigtable中tablet的分层结构:
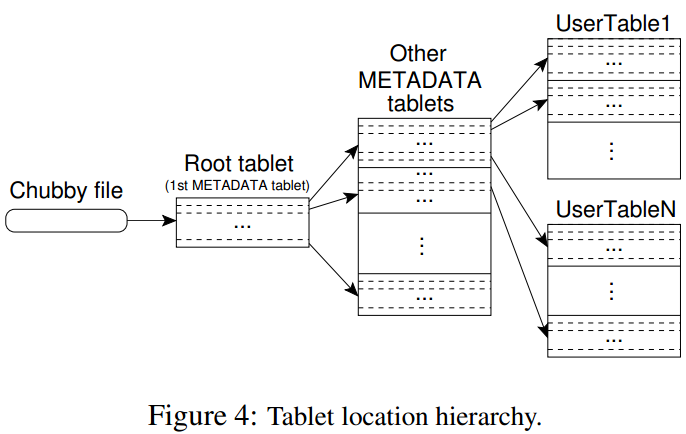
第一层的Chubby包含了root tablet的位置,root table是METADATA table的第一个tablet,存储了其余MEATADATA tablet的位置,且不可拆分,保证了整体最多三层的结构。METADATA tablet存储了各张表的位置,每条记录1KB左右,METADATA总大小限制在128MB,已经足够绝大多数系统使用。
在此架构上,一个client进行寻址需要访问3次(从访问Chubby开始),如果缓存过期,则最多需要6次访问。且只需要访问内存数据。同时还会通过一次性读多个tablet来预读取进行进一步优化。
为什么缓存失效时需要读6次?缓存的具体是什么?这不是意味着不用缓存更好么?
Table Assignment
Bigtable使用Chubby来追踪tablet server的在线情况。在线的tablet server会持续占有一个特定文件的锁,如果锁被释放则server也进入不可用状态。如果有一个tablet没有被分配,又有适合的server,master就会向对应的server发送tablet load请求。
使用锁来判定服务是否存在是一个很有趣的方法,具体的逻辑如下:
- master发现有server释放了锁,或是某个server的最近几次请求均失败。
- master尝试申请该server占有的锁。
- 获取锁成功,说明master和Chubby存活,server宕机,master删除该server信息,进行tablets的重新分配
如果tablet server意外宕机,并没有主动释放锁,那么锁何时会释放?是否是通过过期时间?
而如果master无法和Chubby通信,自己的session过期,就会主动kill自己。此时重启一台master,做如下操作:
- 向Chubby获取一个master锁,保证没有其它的master节点启动。
- 扫描Chubby中的server信息。
- 和每个tablet server交互获取tablet分配信息。
- 扫描METADATA table,没有被分配的tablet放入未分配组,等待进行分配。
tablets会发生新建,删除,合并和分裂操作,前三者均有master发起,最后一点由tablet server触发,并会将记录上报给METADATA table,并通知master。
Tablet Serving
Tablet的工作流大致如下图:

当写请求来时,会进行权限校验,然后记录到tablet log中去。最新的修改存入内存中的memtable,老的请求写到GFS上的SSTable Files中去落盘。
如果需要恢复一块tablet,就需要从METADATA中读到它的SSTable地址,以及一些日志中的redo points,将SSTable读到内存并重做日志记录,重构memtable。
对于读请求,则在权限校验后,将需要的SSTable内容和memtable内容组合起来发给Client。
Compactions
对于上一小节中写操作,具体来说,当memtable不断变大并达到一定阈值时,就会被冻结并由一个新的memtable接受输入。被冻结的memtable则转化为SSTable存入GFS。此时就能清理server的内存,同时也可以减少log中的对应日志。这一操作被称为“minor compaction”。
而由于通过minor compaction生成的SSTable比较小,后台任务还会定时合并这些SSTable和memtable到一个SSTale中去,称为“major compaction”。在minor compaction中生成SSTable可能包含已删除的数据,而在经过major compaction后就会实际删除数据,回收对应空间。
Refinement
在实际使用过程中,还可以通过很多方式对Bigtable进行调优:
- Locality Groups:Client可以将通常一起使用的Column family组织在一起成为一个locality group,在每个table中,不同的locality group可以存入不同的SSTable,提升读取效率。同时还可以设置locality group通过懒加载放入内存,这对小量高频数据是否有效,例如系统中的METADATA table。
- Compression:Client可以设置将locality group压缩在一起,并指定压缩格式。可以分离压缩locality group,虽然会有一些空间损失,但单独读取某个group就不再需要解压了。Client常用自定义的两轮压缩:第一遍是Bentley and McIlroy’s scheme,第二遍是使用快速压缩算法。对语义相近的数据进行压缩,压缩比会很高。
- Caching for read performance:为了提高读效率,可以进行双重缓存。Scan cache缓存键值对,Block Cache缓存读到的SSTalbe block。Scan cache有利于不断读取同样的数据,而Block Cache则利用局部性快速读到相邻的数据。
- Bloom filters:使用Bloom filter允许操作时过滤掉不包含所需行列的SSTable,从而减少磁盘读写。
- Commit-log implementation:在实现commit log时,每个tablet server只读写一个log文件。这样会大大优化读写log文件的效率,但在tablet恢复时会比较痛苦:每恢复一个tablet都需要读所有的日志。此时会先对日志记录进行按<table, row name, log sequence number>的排序。作排序时,会把log文件切分成64MB的小块,并行进行。为了避免一些网络问题等阻塞,每个tablet server写日志会有两个线程,每个线程写自己的log文件。同一时间只有一个线程活跃,在当前活跃线程性能不佳时进行切换,并通过对日志编号清除重复写入的部分。
- Speeding up tablet recovery:在tablet进行转移时,会先作一次minor compaction,减少需要从log中恢复的操作。完成后, server不再对该tablet提供服务,此时再对第一次开始compaction后又进入的操作做第二次minor compaction。这样迁移到新的server后就不需要做任何的从log恢复的工作。
- Exploiting immutability:在服务过程中,SSTable是不变的,不需要做并发控制。只有memtable是不断变化的。这样理解:存入SSTable后数据不变,变动都存在memtable中,在compaction时才会把变动落盘到SSTable。
Performance Evaluation
这一章还是一贯的实验验证环节。实验结果当然表明Bigtable设计不错,但也有几点值得注意:
- 随机读的性能比其它操作性能都差。或者说读性能(从磁盘)要差于写性能。原因是读操作需要将数据从GFS将不同的SSTable内容读到tablet server,每读1000byte,就需要把整个64KB的数据读出。所有的写操作只是写入日志,然后使用批量commit stream高效地写给GFS。而Scan操作可能更接近于我们平时理解的读操作,其性能也最好。
- 随机写和顺序写性能没什么差别,因为它们的操作是一致的。
Real Applications
Google内部有不少系统使用了Bigtable来进行存储。2006年8月时,就有388个Bigtable cluster,使用了24,500台tablet server。真实应用包括Google Analytics,Google Earch,Personalized Search等。
Lessons
在构建分布式系统的过程中,Google工程师经历了很多种类型的服务失效。分布式服务本身是很脆弱的。
另一点教训是工程迭代时,放缓上新特征的速度,把新特性的用途探究清楚。
第三点是系统级别的监控很有必要,能够帮助快速定位问题。
而最重要的一点则是简洁的设计很有价值。能够指导整个工程的开发。
而我读完文章的主要感受是:文章中充满了各种工程设计和优化细节,这些工程细节通常都是最后的10%,也是把一个不错的系统变成一个优秀系统的10%。做任何事都不能忽视最后的10%。
Six Questions
这个技术出现的背景、初衷和要达到什么样的目标或是要解决什么样的问题。
相较于比较底层GFS文件存储系统,Bigtable已经运行在业务层次,会要求数据进行结构化。其本质接近于一个分布式的数据库。在有了GFS后,Google工程师面临的一个现实问题就是:如何利用分布式文件系统将结构化的数据存储下来?更明确一些的需求,例如:如何将Google将要使用到的庞大的网页索引数据存下来,能做到快速的访问,还能很好地做版本维护?另外,Google还有很多的机器学习任务,需要在后台访问非常大的数据集,这部分请求对延时就不太敏感。这些场景可以集成在一个数据库中吗?
这个技术的优势和劣势分别是什么,或者说,这个技术的trade-off是什么。
面对分布式系统,一个必须要谈的trade-off就是CAP。P是不可避免的,而Bigtable更加注重C,通过Chubby来实现一致性。但会牺牲一定的可用性A(当出现分区时,直接干掉不能通信的节点)。
另外,Bigtable实现了行的原子性操作,实现了key-value形式的NoSQL存储,但放弃了跨行的事务操作。
这个技术使用的场景。
如第一问中所述,Bigtable被实际应用于Google的很多产品中,从Google搜索引擎的网络索引,到Google Earth的地理信息等等。作为一个NoSQL的数据库,同时是一个类似于“宽列”数据库,它适用于对“关系”没有强烈要求的应用。且最好是需要大量顺序读取数据的场景。
技术的组成部分和关键点。
Bigtable的组成部分有三个:客户端接入的library,一台master server和许多的tablet server。
技术的底层原理和关键实现。
Bigtable本身使用GFS来存储文件,同时使用Chubby来处理分布式锁。而对于同一个数据的更新,Bigtable使用了Log-Structured Merge Tree来记录。
已有的实现和它之间的对比。
根据论文的相关工作,可比较的实现包括:Boxwood,CAN,Chord,Tapestry,Pastry,Oracle的Real Application Cluster Database,IBM的DB2等。
与Boxwood相比,Boxwood与Chubby+GFS+Bigtable的功能有不少重合处。在功能重合的点上,Boxwood的组件更加底层,其目标是为更高层的服务,例如文件系统或数据库来提供基础设施。而Bigtable则是直接支持应用来存储数据。
CAN,Chord,Tapestry和Pastry这些分布式数据存储系统工作在一个不受信任的网络上,不稳定的变化的带宽,不受信任的客户端,频繁的配置更改以及拜占庭将军问题等是这些系统关注的重点。
Real Application Cluster Database和DB2均使用事务实现了完整的关系模型。
有不少系统和Bigtable一样,使用了列式存储而非基于行存储,包括C-Store,Sybase IQ,SenSage,KDB+,MonetDB/X100的ColumnBM存储层等。
文中还罗列了一些细节实现上的差异,这里还要讲一下在此之后实现的Amazon DynamoDB,DynamoDB最大的区别就是更加倾向于实现AP而非CP,具体在后面的博客中描述。