分布式存储研究计划的最后一篇论文,研读Amazon的Aurora数据库。其对应论文为:Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases。论文发表于2017数据库顶会SIGMOD。键值对数据库,Amazon提出了Dynamo,而关系型数据库,Amazon推出了Aurora。
Introduction
随着数据库上云,传统数据库的业务IO瓶颈已经转化为数据库层和数据存储层之间的IO瓶颈,在这种情况下,外部存储节点、磁盘和网络路径对于响应时间有很大的影响。另外,一些同步操作会导致数据库延迟和环境切换。还有,事务提交也会很大程度上影响性能,尤其是2阶段提交等复杂操作。
相对应的,Aurora有以下优点:
- 使用了一个独立的,能容忍错误并自我修复的跨数据中心存储服务,保证了数据库不受网络层或数据存储层问题的影响。
- 在数据存储中,只写入redo log记录,可以从量级上减少网络IOPS。
- 将耗时复杂的功能从一次昂贵的操作转变为连续的异步操作,保证这些操作不会影响前台处理。
Durability at Scale
为了保障大规模集群下的耐久性,Aurora主要有两项措施:使用一个仲裁模型(quorum model)以及分段存储。
仲裁模型,我们已经比较熟悉了,对于V个副本的数据,R + W > V即可保证一致性。在之前的Dynamo论文中也有提到。一个典型的取值是(V,R,W)=(3,2,2)。但Aurora认为这还不够。一个简单的例子是,将数据的三个副本分别放在三个可用区(AWS的AZ概念,在同一个地区相邻的三个数据节点),如果同时一个可用区发生了大规模故障,而另一个可用区里的一台服务器发生了偶然故障,那么仲裁模型将不再有效。
为了保障(a)即便整个可用区加一台其它可用区服务器发生故障,系统不会丢失数据,以及(b)一整个可用区故障后仍能进行写数据,Aurora的参数设置为(V,R,W)=(6,3,4),每个可用区会有两个数据副本。可以看到(a)情况下,3个副本发生故障,不影响读操作,数据不丢失。而(b)情况下,2个副本故障,不会影响写操作。
Segmented Storage
故障恢复有两个概念:MTTF(Mean Time to Failure,平均故障发生时间)和MTTR(Meat Time to Repair,平均故障修复时间)。如果希望系统能够抵御故障,那么需要MTTF > MTTR,在故障修复期中尽可能没有新的故障发生。MTTF很难优化,Aurora专注于降低MTTR,策略也很直观:将数据分段为10GB的Segment,每份会在3个可用区中有一共6个副本,数据存储在带有SSD的EC2上(亚马逊的虚拟服务器)。那么Segment就是系统探测失效和修复的最小单元。10GB的分段数据在10Gbps的网络连接上只需要10s就能传输完毕,在这个窗口内1个可用区失效,外加另外可用区中两个副本同时失效的概率非常非常低。
Operational Advantages of Resilience
由于整个Aurora的设计针对故障保证了高可用性,那么利用这个高可用性也可以做很多运维操作。例如回滚一次错误的部署;标记过热的节点为已损坏,由系统重新将其数据分配到冷节点中去;以及停止节点为其打上系统和安全补丁。其中,打补丁时,会一个个可用区依次进行,同一时间一份数据只会有一个副本所在节点进行打补丁操作。
The Log is The Database
The Burden of Amplified Writes
Aurora在提供了强大的高可用性背后,实际放大了整个数据库读写的操作。例如一个MySQL的写操作需要写4次,在写的过程中,实际上分为了很多类的数据,包括redo log、binaray log(会被同步归档在S3中来支持实时restore)、修改的数据页、临时的double-write以及FRM元数据。所有数据都会在节点间传播和写入数据库。被放大了的网络负载如图:
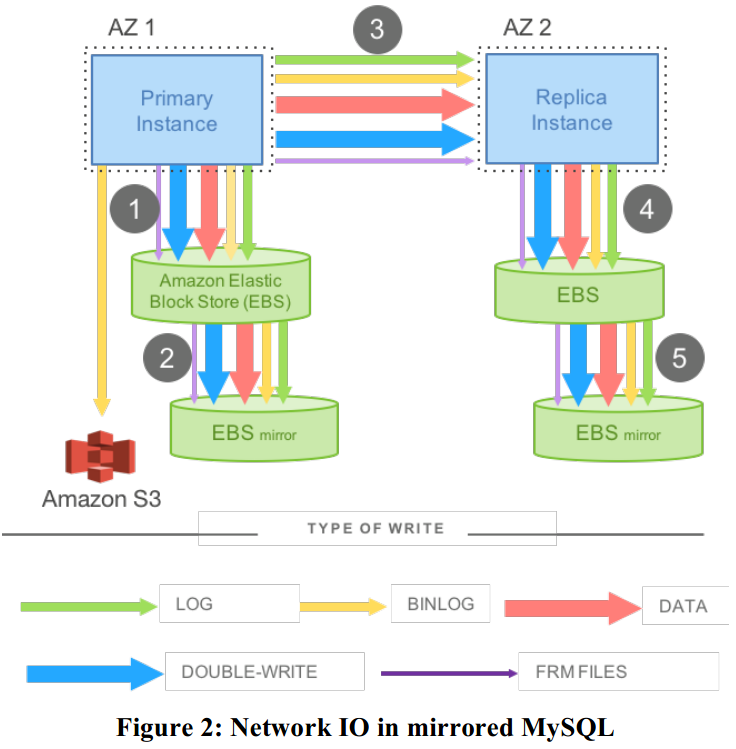
Offloading Redo Processing to Storage
为了解决上述的问题,在Aurora中,在网络中传播的写数据只有redo log。在将log传递到数据存储层后,再在后台或按需生成数据库的页。因此也才有了标题“The log is the database”。优化后的网络负载如图:
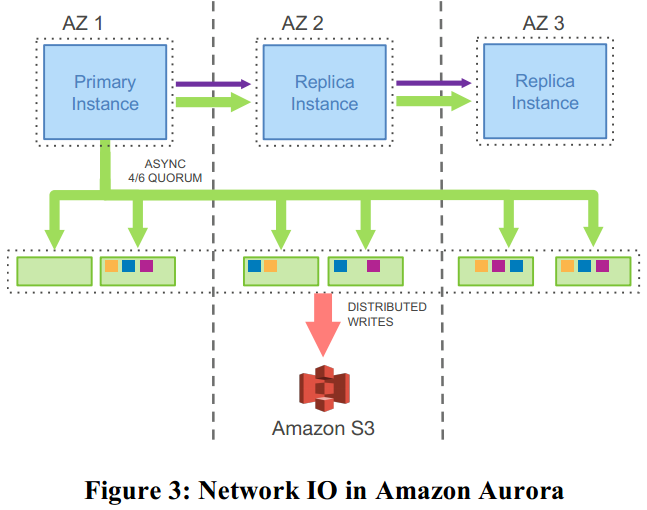
经过实验对比,这项优化达成了其同一时间处理的事务量提高到了35倍,优化前每个事务处理的I/O数量是优化后的7.7倍,以及更多数据上的性能提高。性能的提高也意味着系统可用性的升级,降低了故障恢复时间。
Storage Service Design Points
Aurora的一项核心设计理念,就是把大部分的存储操作放到后台,精简前台的处理以缩短响应时间。分离前后台的做法让整个系统更加灵活。例如在CPU忙于处理前台请求的时候,就可以暂时不用管旧页面的垃圾回收。后台处理与前台处理呈现负相关的关系,互相削峰填谷。一个更加细致的存储节点交互如图:
- 接收到日志记录,并填入一个内存队列。
- 在磁盘上将记录持久化,并返回一个应答。
- 整理记录,并检查是否有因为一些操作丢失导致的记录差异。
- 通过Gossip和其它节点交流填补差距。
- 将日志记录合并到新的数据页中去。
- 定期将日志和新页面备份到S3。
- 定期进行垃圾回收,清理掉无用的旧版本数据。
- 定期进行CRC校验。
其中只有第1第2步涉及前台交互,影响响应时间。
The Log Marches Forward
这节的标题起的很有意思,内容主要讲的就是Aurora如何在不使用复杂的2PC协议的情况下进行多个状态(durable,runtime,replica)的数据同步。
Solution Sketch: Asynchronous Processing
Aurora的一个设计亮点就是redo log的日志流处理。这个log不单单是一个顺序队列,实际上会和一个单调递增的序列号(LSN,Log Sequence Number)相关联。每个节点都有可能丢失几个操作,此时它会和与它存储同一份数据的节点进行Gossip交流,填补缺失。这样正常的读操作(没有发生故障恢复)就可以只读一个分片,避免仲裁读取的方法(在之后会有更详细的解释)。
而当需要进行故障恢复时,Aurora首先会保证所有节点上的数据一致。使用的就是LSN。在数据恢复时,系统先确定一个保证可用的最高LSN,称为VCL(Volume Complete LSN),任何LSN高于VCL的日志记录会被截断。数据库还可以进一步规定只有某些LSN能够被作为截断点,称之为CPL(Consistency Point LSNs),而定义VDL(Volume Durable LSN)为小于等于VCL的最大CPL。术语有些多,给一个简单的例子:当前日志的LSN已经达到了1007,但数据库定义CPL为900,1000,1100这些特定值。那么我们就需要在1000这个值进行截断,1000即为VDL。实际过程中的大致流程如下:
- 每个数据库层事务被切分成多个有序且可被原子操作的小事务(mini-transactions,MTRs)
- 每个MTR由多个连续的log record组成。
- 一个MTR的最后一个log record被认为是一个CPL。
从这段描述可以看出,一个CPL其实就是一个原子MTR的结束标志。
Normal Operation
接下来详细介绍一下每种操作的具体原理。包括write,read,commit和replica。
- Writes:当数据库收到一批log日志的write quorum的确认后,就会向前推进当前的VDL。在每一时刻,会有很多事务在同时进行,数据库会为每个日志分配一个唯一有序的LSN,同时LSN要小于当前VDL和LAL(LSN Allocation Lmit)的和。这段话翻译有些生硬,其实就是为了防止前台操作太快,后台存储系统处理不过来,LSN不能超前VDL太多,其差值最大为LAL,目前设置为10M。同时,为了解决每个分片可能存在的日志丢失问题,每个日志都有一个向前的回链(像是一个反向链表),通过向前回溯,以及Gossip交互,可以为各个节点构建一个完整的日志记录,称之为SCL(Segement Complete LSN),也即所有日志到达了所有节点的最大LSN。
- Commits:Aurora的事务提交是完全异步的。工作线程收到commit请求,在一个等待commit的事务列表中记录它的commit LSN,然后就继续处理其它请求。有一个专门的线程在VDL推进时,判断列表中有哪些LSN小于等于VDL,然后将这些事务的应答推回给还在等待的客户端。
- Reads:Aurora和很多其它数据库一样,数据页会放在缓存中,命中丢失时才会做一次IO请求,当缓存满时,系统会根据特定的算法汰换数据页。Aurora不一样的是,它要求在缓存中的page LSN一定要大于等于VDL。从而保证在这个数据页中所有请求都已经写到log,且可以通过VDL始终获取到最新的持久化数据。也因此,正常的读取只需要读一个满足条件的分片就足够了。
- Replicas:在Aurora中,一个存储磁盘可以挂载一个writer和最多15个read副本。增加一个read副本不会对性能有什么影响。为了加快响应,写请求生成的日志流也会被发送到所有读副本中去。如果这个写请求涉及到当前缓存中的某个数据页,那就把这个请求更新到数据页中,否则就直接丢弃了。这里读副本消费请求是异步的,需要遵循两条规则:一是会更新到数据页的请求,其LSN需要小于等于VDL。二是mini-transaction的修改需要原子性的写入缓存,以保障数据一致性。
Recovery
传统的数据库Recovery会使用类似ARIES的协议,根据WAL(write-ahead log),使得故障恢复后的各个节点数据一致。这种方法的一个原则是在数据库故障离线期间,通过重放日志的方式来恢复数据。而Aurora则将重放的过程放到了数据存储节点,完全后台话操作。即使故障发生时正在处理100K TPS,也能在10秒内恢复。
当然,在故障恢复后,系统还需要重新构建它的运行时状态(runtime state)。此时的读取就需要进行quorum读,来保障数据一致性。同时进行VDL的计算,截断之后的record。数据库也需要对一些操作做回滚,但这些操作都可以在后台进行。
Putting It All Together
整个Aurora的鸟试图如下:
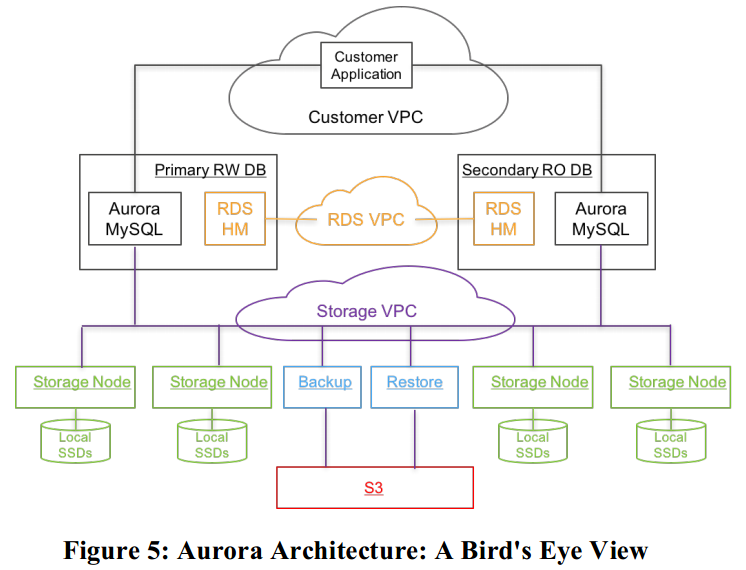
其中数据库引擎就是社区版的MySQL/InnoDB。做的最主要的改变就是InnoDB向磁盘读写数据的方式。
在社区版InnoDB中,写操作会将数据写入缓存页,相关的redo log record以LSN的顺序写到WAL的缓存中。在事务提交中,WAL协议只要求redo log records持久化写到磁盘中,实际修改的缓存页通过double-write技术最终写到磁盘上。除了IO子系统,InnoDB还有事务子系统,lock manager,B+树的实现以及MTR。MTR实际就是对一些InnoDB内原子操作的建模,例如B+树的split和merge。
在Aurora中,每个MTR需要进行的redo log records会被组织成批量操作,在所有存储对应数据的分片中共享。这些批量操作会被写到存储服务,最后的一个log record被标记为一致性point。Aurora的读副本会接收到写请求的信息,来支持快照功能。数据库引擎负责了并发控制,而存储服务提供了一个逻辑上与你使用InnoDB写本地存储一致的数据。
在实际部署中,Aurora会在同一个region的不同AZ中分布实例,每个实例中会使用RDS来作为Host Manager,监控集群健康,判断是否需要关闭或一个实例需要被替代。为保障安全,Aurora集群会通过VPC限制互相沟通,其处于三个层次的VPC中:Custom VPC、RDS VPC、Storage VPC。存储服务由一系列EC2承载,如之前所述,至少3个AZ,每个AZ两台EC2。存储管理层会使用DynamoDB来存储集群和节点配置,卷的元数据,及向S3存储数据的详细描述。同时存储管理层会使用Amazon Simple Workflow Service来维持高可用和自动化运维。存储服务的关键点都会有持续监控。
Performance Results
产品上线前,Aurora经过了一系列对比测试。测试结果在原文中罗列,这里不再详细列出。
在实验室测试中,有如下几点结论:
- Aurora可以进行通过扩展实例类型线性扩展其吞吐量。
- Aurora即使在大数据量的情况下,其读写吞吐量也明显优于MySQL。
- 随着客户端连接的增加,Aurora可以线性扩展其吞吐量。
- Aurora相比于MySQL,写延迟非常低(降低几个数量级)
- 在热行争用(hot row contention)的场景下,Aurora的性能也明显由于MySQL。
在真实客户场景下Aurora的性能也得到了很好的证实。
Lessons Learned
- Multi-tenancy and Database Consolidation:许多客户的服务会面临多租户的场景,他们原有的应用不容易拆分,那么简单的方法就是为每个租户维持一张表,并把所有租户的表放到数据库中去。这和类似于Salesforce使用多租户数据结构,并把所有用户数据封装到一个表里的行为不一样。这种场景下,需要考虑以下几个方面,Aurora都非常适合:
- 能够维持高并发
- 能够按用量动态调整数据库大小
- 能够尽量控制多租户数据之间的互相影响。
- High Concurrent Auto-scaling Workloads:Aurora可以很好地处理访问尖峰问题。
- Schema Evolution:在使用数据库时,开发人员可以很轻松地改变schema,而DBA就需要处理这些schema演化(实际上我没有类似的经历,不能很好地想象这种场景)。Aurora提供了两种机制:
- 对各个版本的schema历史做记录,在解析时按需使用对应的schema。
- 使用写时修改为最新Schema的机制,对每个独立的页进行“懒”升级。
- Availability and Software Upgrades:线上应用基本不能接受数据库的停机升级。Aurora发布了一种零停机滚动升级的方式。具体来说,这个机制先找到一台不再处理事务的实例,将程序的临时状态存储到本地,为数据库打补丁,然后重新加载应用状态。
另一个我觉得解读地很好的博客:Amazon Aurora解读
Six Questions
这个技术出现的背景、初衷和要达到什么样的目标或是要解决什么样的问题。
Amazon已经有了DynamoDB这个强大的NoSQL数据库,与之相对应的是一个在线事务处理(On-line Transaction Processing)的关系型数据库Aurora。它的出现源于Amazon的一个观点:在云端大规模集群中,传统的OLTP数据库已经不能保证可用性和持久性。Aurora将传统数据库中的存储和计算分离,在这种分离架构下,关系型数据库的主要瓶颈已经从数据处理和存储的转为了网络传输。因此Aurora的许多设计和优化都是针对此而来:构建一个简单的框架来解决大型数据库中的网络传输瓶颈。
这个技术的优势和劣势分别是什么,或者说,这个技术的trade-off是什么。
Aurora的优势在于,它改变了传统关系型数据库的读写框架,使其适用于弹性伸缩的云端,获得了可用性和持久性,同时降低了网络传输,使得整个系统响应低延时。上云之后,还有更多的优点,例如按需伸缩,多租户共享基础设施降低成本,故障能够快速恢复等。为此它继承了社区版MySQL的一些弱点,比如不能执行复杂的查询,单点写,写水平扩展需要依赖其它中间件方案。同时目前最大支持64TB的数据量。
这个技术使用的场景。
Aurora适用于部署在云端弹性伸缩,读多写少,要求高并发低延时高可用性,处理事务的关系型数据库场景。
技术的组成部分和关键点。
Aurora本质上是将社区版的MySQL进行了重新架构,将计算和存储分离。其关键的组成部分是经过修改的“Aurora MySQL”,配合使用AWS RDS进行元数据管理,并将数据存储到底层的磁盘和S3等存储服务中。
技术的底层原理和关键实现。
Aurora的底层引擎依旧是社区版MySQL,其做的最主要的改进是剥离计算和存储,简化网络传输,在网络传输中只传递redo log。另外就是使用Quorum模型来保证高可用,使用分段存储来保证快速地从故障中恢复。
已有的实现和它之间的对比。
论文本身没有Related Work。根据之前推荐的博客,其一个比较对象就是Google的MySQL数据库Spanner:
| 比较项 | Spanner | Aurora |
|---|---|---|
| 架构 | Shared Nothing | Shared Disk |
| 弹性 | Yes | Yes |
| 持续可用 | Paxos-based | Quorum-based |
| 写扩展 | Yes | No |
| 分库分表透明 | Yes | No |
| 分布式事务 | Yes | No |
| MySQL/Postgres兼容 | No | Yes |