本篇博客翻译自Brendan Gregg的技术考古文章:Linux Load Average: Solving the Mystery。翻阅这篇文章的原因是我在使用Prometheus做系统CPU使用量告警时,一个system_load的指标和自己预期的不太相符:总是在CPU余量还很大的情况下达到告警线。为此研究了一下Linux的Load Average指标。
以下为原文翻译:
Load Average(以下译为平均负载)是工程中一个很重要的指标,我的公司使用该指标以及一些其它指标维持着数以百万计的云端实例进行自动扩容。但围绕着这个Linux指标一直以来都有一些谜团,比如这个指标不仅追踪正在运行的任务,也追踪处于uninterruptible sleep状态(通常是在等待IO)的任务。这到底是为什么呢?我之前从来没有找到过任何解释。因此这篇文章我将解决这个谜题,对平均负载指标做一些总结,供所有尝试理解这一指标的人作为参考。
Linux的平均负载指标,也即“system load average”,指的是系统一段时间内需要执行的线程(任务),也即正在运行加正在等待的线程数的平均数。这个指标度量的是系统需要处理的任务量,可以大于系统实际正在处理的线程数。大部分工具会展示1分钟,5分钟和15分钟的平均值。
1 | uptime |
简单做一些解释:
- 如果averages是0,表示你的系统处于空闲状态。
- 如果1分钟的数值高于5分钟或15分钟的数值,表示系统负载正在上升。
- 如果1分钟的数值低于5分钟或15分钟的数值,表示系统负载正在下降。
- 如果这些数值高于CPU数量,那么你可能面临着一个性能问题。(当然也要看具体情况)
通过一组三个数值,你可以看出系统负载是在上升还是下降,这对于你监测系统状况非常有用。而作为独立数值,这项指标也可以用作制定云端服务自动扩容的规则。但如果想要更细致地理解这些数值的含义,你还需要一些其它指标的帮助。一个单独的值,比如23-25,本身是没有任何意义的。但如果知道CPU的数量,这个值就能代表一个CPU-bound工作负载。
与其尝试对平均负载进行排错,我更习惯于观察其它几个指标。这些指标将在后面的“更好的指标(Better Metrics)”一章介绍。
历史
最初的平均负载指标只显示对CPU的需求:也即正在运行的程序数量加等待运行的程序数量。在1973年8月发表的名为“TENEX Load Average”RFC546文档中有很好的描述:
[1] The TENEX load average is a measure of CPU demand.
The load average is an average of the number of runnable processes over a given time period.
For example, an hourly load average of 10 would mean that (for a single CPU system) at any time during that hour one could expect to see 1 process running and 9 others ready to run (i.e., not blocked for I/O) waiting for the CPU.
这篇文章还链向了一篇PDF文档,展示了一幅1973年7月手绘的平均负载图(如下所示),表明这个指标已经被使用了几十年。
如今,这些古老的操作系统源码仍然能在网上找到,以下代码片段节选自TENEX(1970年代早期)SCHED.MAC的宏观汇编程序:
1 | NRJAVS==3 ;NUMBER OF LOAD AVERAGES WE MAINTAIN |
以下是当今Linux源码的一个片段(include/linux/sched/loadavg.h):
1 |
Linux也硬编码了1,5,15分钟这三个常量。
在更老的系统中也有类似的平均负载比如Multics就有一个指数调度队列平均值(exponential scheduling queue average)。
三个数字
标题的三个数字指的是1分钟,5分钟,15分钟的平均负载。但要注意的是这三个数字并不是真正的“平均”,统计时间也不是真正的1分钟,5分钟和15分钟。从之前的汇编代码可以看出,1,5,15是等式中的一个常量,而这个等式实际计算的是平均每5s的指数衰减移动和(exponentially-damped moving sums)(译者:如果你和我一样对这个名词和公式一头雾水,本节随后有相关文章和代码链接)。这样计算出来的1,5,15分钟数值能更好地反应平均负载。
如果你拿一台空闲的机器,然后开启一个单线程CPU-bound的程序(例如一个单线程循环),那么60s后1min平均负载的值应该是多少?如果只是单纯的平均,那么这个值应该是1.0。但实际实验结果如下图所示:
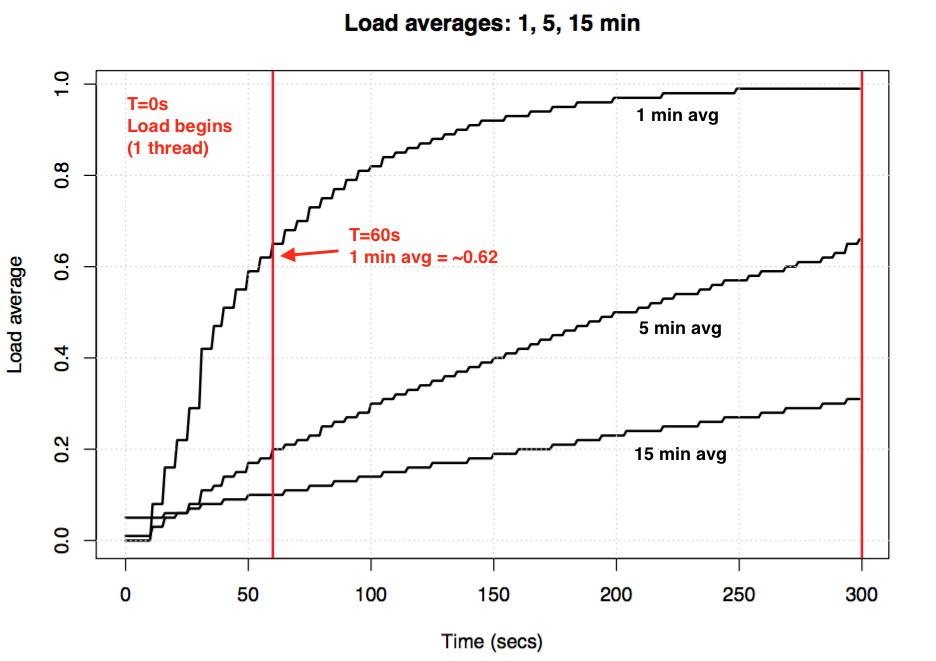
被称作“1分钟平均负载”的值在1分钟的点只达到了0.62。如果想要了解更多关于这个等式和类似的实验,Neil Gunther博士写了一篇文章:How It Works,而loadavg.c这段linux源码也有很多相关计算的注释。
Linux不可中断任务(Uninterruptible Tasks)
当平均负载指标第一次出现在linux中时,它们和其它操作系统一样,反映了对CPU的需求。但随后,Linux对它们做了修改,不仅包含了可运行的任务,也包含了处在不可中断(TASK_UNINTERRUPTIBLE or nr_uninterruptible)状态的任务。这个状态表示程序不想被信号量打断,例如正处于磁盘I/O或某些锁中的任务。你以前可能也通过ps或者top命令观察到过这些任务,它们的状态被标志为“D”。ps指令的man page对此这么解释:“uninterrupible sleep(usually IO)”。
加入了不可中断状态,意味着Linux的平均负载不仅会因为CPU使用上升,也会因为一次磁盘(或者NFS)负载而上升。如果你熟悉其它操作系统以及它们的CPU平均负载概念,那么包含不可中断状态的Linux的平均负载在一开始会让人难以理解。
为什么呢?为什么Linux要这么做?
有无数的关于平均负载的文章指出Linux加入了nr_uninterruptible,但我没有见过任何一篇解释过这么做的原因,甚至连对原因的大胆猜测都没有。我个人猜测这是为了让指标表示更广义的对资源的需求的概念,而不仅仅是对CPU资源的需求。
搜寻一个古老的Linux补丁
想了解Linux中一个东西为什么被改变了很简单:你可以带着问题找到这个文件的git提交历史,读一读它的改动说明。我查看了loadavg.c的改动历史,但添加不可中断状态的代码是从一个更早的文件拷贝过来的。我又查看了那个更早的文件,但这条路也走不通:这段代码穿插在几个不同的文件中。我希望找到一条捷径,就使用git log -p下载了整个包含了4G文本文件的Linux github库,想回溯看这段代码第一次出现在什么时候,但这也是条死路:在整个Linux工程中,最老的改动要追溯到2005年,Linux引入了2.6.12-rc2版本的时候,但这个修改此时已经存在了。
在网上还有Linux的历史版本库(这里和这里),但在这些库中也没有关于这个改动的描述。为了最起码找到这个改动是什么时候产生的,我在kernel.org搜索了源码,发现这个改动在0.99.15已经有了,而0.99.13还没有,但是0.99.14版本丢失了。我又在其它地方找到了这个版本,并且确认改动是在1993年11月在Linux 0.99 patchlevel 14上实现的。寄希望于Linus在0.99.14的发布描述中会解释为什么改动,但结果也是死胡同:
“Changes to the last official release (p13) are too numerous to mention (or even to remember)…” – Linus
他提到了很多主要改动,但并没有解释平均负载的修改。
基于这个时间点,我想在关键邮件列表存档中查找真正的补丁源头,但最老的一封邮件时间是1995年6月,系统管理员写下:
“While working on a system to make these mailing archives scale more effecitvely I accidently destroyed the current set of archives (ah whoops).”
我的探寻之路仿佛被诅咒了。幸运的是,我找到了一些更老的从备份服务器中恢复出来的linux-devel邮件列表存档,它们用tar压缩包的形式存储着摘要。我搜索了6000个摘要,包含了98000封邮件,其中30000封来自1993年。但不知为何,这些邮件都已经遗失了。看来原始补丁的描述很可能已经永久丢失了,为什么这么做仍然是一个谜。
“不可中断”的起源
谢天谢地,我最终在oldlinux.org网站上一个来自于1993年的邮箱压缩文件中找到了这个改动,内容如下:
1 | From: Matthias Urlichs <urlichs@smurf.sub.org> |
这种阅读24年前一个改动背后想法的感觉很奇妙。
这证实了关于平均负载的改动是有意为之,目的是为了反映对CPU以及对其它系统资源的需求。Linux的这项指标从“CPU load average”变为了“system load average”。
邮件中举的使用更慢的磁盘的例子很有道理:通过降低系统性能,对系统资源的需求应该增加。但当使用了更慢的磁盘时,平均负载指标实际上降低了。因为这些指标只跟踪了处在CPU运行状态的任务,没有考虑处在磁盘交换状态的任务。Matthias认为这不符合直觉,因此他做了相应的修改。
“不可中断”的今日
一个问题是,今天如果你发现有时系统的平均负载过高,光靠disk I/O是否已经不足以解释?答案是肯定的,因为我会猜测Linux代码中加入了1993年时并不存在的设置TASK_UNINTERRUPTIBLE分支,进而导致平均负载过高。在Linux 0.99.14中,有13条代码路径将任务状态设置为TASK_UNINTERRUPIBLE或是TASK_SWAPPING(之后这个状态被从Linux中移除了)。时至今日,在Linux 4.12中,有接近400条代码分支设置了TASK_INTERRUPTIBLE状态,包括了一些加锁机制。很有可能其中的一些分支不应该被包括在平均负载统计中。下次如果我发现平均负载很高的情况,我会检查是否进入了不应被包含的分支,并看一下是否能进行一些修正。
我为此第一次给Matthias发了邮件,来问一问他当下对24年前改动的看法。他在一个小时内(就像我在twitter中说的一样)就回复了我,内容如下:
“The point of “load average” is to arrive at a number relating how busy the system is from a human point of view. TASK_UNINTERRUPTIBLE means (meant?) that the process is waiting for something like a disk read which contributes to system load. A heavily disk-bound system might be extremely sluggish but only have a TASK_RUNNING average of 0.1, which doesn’t help anybody.”
(能这么快地收到回复,其实光是收到回复,就已经让我兴奋不已了,感谢!)
所以Matthias仍然认为这个指标是合理的,至少给出了原本TASK_UNINTERRUPTIBLE的含义。
但Linux衍化至今,TASK_UNINTERRUPIBLE代表了更多东西。我们是否应该把平均负载指标变为仅仅表征CPU和disk需求的指标呢?Scheduler的维护者Peter Zijstra已经给我发了一个取巧的方式:在平均负载中使用task_struct->in_iowait来代替TASK_UNINTERRUPTIBLE,用以更紧密地匹配磁盘I/O。这就引出了另外一个问题:到底什么才是我们想要的呢?我们想要的是度量系统的线程需求,还是想要分析系统的物理资源需求?如果是前者,那么等待不可中断锁的任务也应该包括在内,它们并不是空闲的。从这个角度考虑,平均负载指标当前的工作方式可能恰是我们所期望的。
为了更好地理解“不可中断”的代码分支,我更乐于做一些实际分析。我们可以检测不同的例子,量化执行时间,来看一下平均负载指标是否合理。
度量不可中断的任务
下面是一台生产环境服务器的Off-CPU火焰图,我过滤出了60秒内的内核栈中处于TASK_UNINTERRUPTIBLE状态的任务,这可以提供很多指向了uninterruptible代码分支的例子: