最近在使用Opentracing + Jaeger监控自己的云端微服务程序时,遇到了难以排查的内存泄露问题。在进行性能测试时,内存中堆满了JaegerSpan,JaegerSpanContext,以及其中的字符串,看代码却不知从何下手排查。
因此翻译这篇来自Kiali开发工程师Juraci Paixao Kroehling的文章The Life of a Span,来了解一下Span的生命周期,希望能给问题排查带来一些启发。
“Span”是分布式链路追踪中的一个独立单元,本篇文章将使用一个Jaeger应用的例子来展示span的生命周期,以及span是如何到达后台收集分析系统的。
在OpenTracing,以及很多其它分布式链路追踪的世界里,“Span”描述的是一个存储独立工作单元信息的数据结构。在大多数案例中,程序员只会关注如何实例化一个tracer,并且使用各种工具库来记录感兴趣的Span数据,至于Span是如何到达后端收集服务如Jaeger的,大多数程序员并不清楚。
今天就让我们来一探魔法背后的奥秘。
在后续的文字中,我们会聚焦于默认配置下所有组件的工作方式,这样你就能清楚比对各个配置项之间的差异,并根据自己所作的配置知道自己的分布式链路追踪在后台是如何工作的了。
我们会使用Jaeger Java Client的一个应用示例来进行说明,其它语言的jaeger client库也是基于类似原理进行工作。
应用配置
这篇博客中使用的例子非常简单,不会像通常大家做的那样在GlobalTracer中注册追踪器。例子只会启动一个Eclipse Vert.x,然后为receiver接收到的每个HTTP请求创建Span。例子中的代码可以在GitLab上找到,摘录最关键的部分如下:
1 | package com.example.demo; |
在启动过程中,Jaeger Java Client会在背后创建一个RemoteReporter实例,从而启动一个守护线程来不断冲刷缓存中存储的Span(参见JAEGER_REPORTER_FLUSH_INTERVAL)。
这个Reporter会创建一个UdpSender实例,使用UDP和Thrift协议来向localhost运行的Jaeger Agent发送抓取到的Span信息。可以使用一个HttpSender来代替默认的UdpSender,这取决于追踪器的配置。
创建Span
一旦工具库,或者业务代码启动了一个Span,Jaeger Java Client将会使用JaegerTracer.SpanBuilder来生成一个JaegerS的实例。这个实例会包含一个上下文对象(JaegerSpanContext)的引用。上下文中有一个TraceId以及一个SpanId,都会与Span树的根节点(也叫Parent Span)保持一致。
Span上报
创建完Span之后,我们的工具库代码就会做一些指定的处理,例如加一个指定的HTTP头部,以及把回复写到Client中去。一旦这些处理完成,try-with-resource语句就会自动调用close()方法,而这个方法又会调用JaegerSpan#finish()。然后span就被JaegerTracer传递到RemoteReporter,此时我们的span长这样:
1 | JaegerSpan( |
RemoteReporter做的事很简单,它会把Span添加到一个队列中,然后就把控制权交还给调用者。因此在真实应用被追踪的过程中,不会发生IO-blocking的处理,更不用说主线程会为span做什么额外工作。
冲刷!
一旦span进入队列中,后台线程就会调用UdpSender#append(JaegerSpan),把每个JaegerSpan转换成Thrift span,然后把它们传递给agent。在转换之后,我们的span长这样:
1 | Span( |
这个Thrift形式的span会被添加到一个缓冲区中,同时sender会监视缓冲区大小,一旦达到UDP报文的最大值(大概65KB),或者达到预定的时间阈值,UdpSender就会加上一个Process对象一起冲刷span队列,也就是追踪器调用UdpSender#send(Process, List
1 | \ufffd\ufffd\u0001\temitBatch\u001c\u001c\u0018\u0011vertx-create-span\u0019<\u0018\u0008hostname\u0015\u0000\u0018\u0... |
Agent中的快闪
Jaeger Agent是紧挨着被追踪程序的一个守护程序,它唯一的目的就是捕捉应用通过UDP提交的Span,并把Span通过一个保持连接的TChannel传递到数据采集器。
Agent接收到的一批Span被称为“batch”,主要有两个属性:一个表示Jaeger Tracer所在进程元数据的Process,以及一组Span。对于这一组Span来说,它们的元数据都是一样的,因此在一个batch中表示可能可以节省一些开销。在我们的例子中,一个batch只有一个span,在被传递到collector前,它长这样:
1 | Batch({ |
抵达收集器
Span结束了它在agent中的闪现,然后就会通过SpanHandler#SubmitBatches中的TChannel处理器(这个处理器只负责处理成Jaeger格式的batch,其它格式例如Zipkin会由其它处理器负责)传递到Jaeger收集器。
Batch被提交到收集器后,带格式的负载长这样:
1 | [ |
Span处理器会把它处理成Jaeger格式,每个Span带上一个Process对象的copy,然后将处理后的队列传递到SpanProcessor#ProcessSpans。我们的Span现在长这样:
1 | [ |
到了这一步,Span有可能会走一个预处理流程,也有可能直接被过滤掉。在通常情况下,Span会抵达SpanProcessor#saveSpan,如果我们的batch中有更多的span,就会看到每个span都会调用这个方法。这时一个Span Writer会被注入来进行处理,这个writer可能是Cassandra,ElastiSearch,Kafka或者内存writer,将Span写入对应区域。
在这些集中储存区中的Span长什么样,就留给读者自己探寻。在Span转换成Cassandra或Elasticsearch语义文件之后,可能会包含大量的细节。
在此之后,我们就不再使用“Span”粒度进行阐述了。以后的场景中,我们观察到的是一个由很多独立span构成的成熟的追踪链路。
UI和查询
到了这个阶段,我们的追踪链路就躺在存储区,等待着UI系统通过查询语句来进行检索。
在Jager UI中,我们可以基于service name(在我们的例子中就是vertx-create-span)等查询术语来搜索追踪链路。在后台,当我们选择了service name,然后点击“Find Traces”,Jaeger查询语句会被组织成如下形式:
1 | { |
查询的APIHandler#Search方法会解析查询术语,然后传递到各存储器特定的Span Reader中。基于service name,我们的链路会被找到并添加到结果列表,在后台这个列表是这样的:
1 | { |
所有的消息在后台被组织成特定格式,然后UI会收到这样的数据:
1 | { |
根据这个格式,Jaeger UI会迭代处理结果,并把它们的信息漂亮地展示在屏幕上:
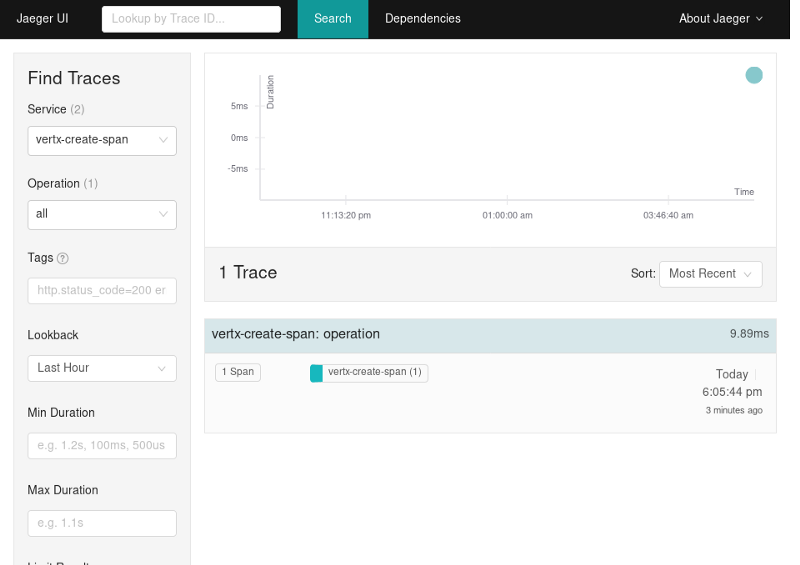
在大多数场景中,点击屏幕上展示的链路不会触发UI的再次查询。但如果我们打开链路,并且点击了“Refresh”,UI就会执行一个ApiHandler#getTrace查询。这个查询根据给定的ID从存储区中查询所有相关span,然后回复一个类似下面这样的数据结构:
1 | { |
由于我们只有一条链路,其中也只有一个span,因此UI获得的payload与之前通过“search”操作获得的一样。不过数据展示方式不同:
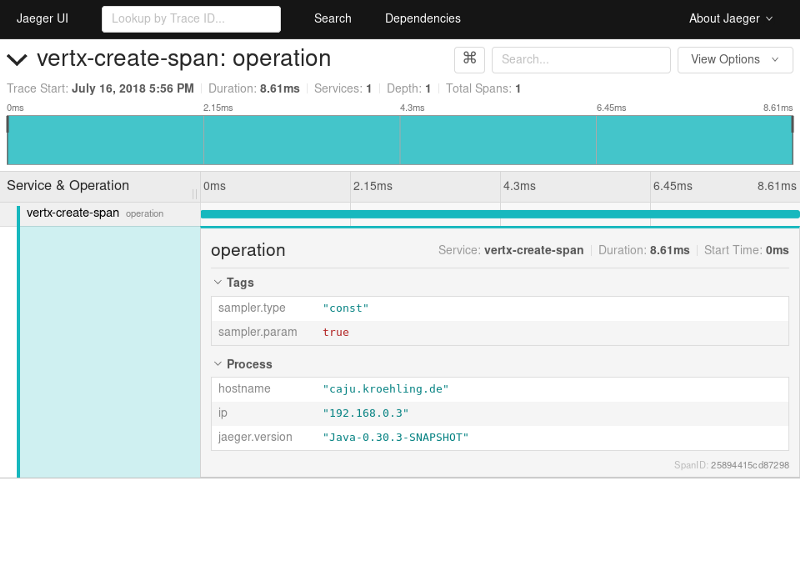
Span来世
到此我们已经几乎覆盖了Span生命的所有阶段,从它的起源直到最终它上报所追踪应用的信息。从此之后,Span还有可能在一些来世场景出现,例如成为Prometheus中的一个数据点,或者在Grafana dashboard中和其它Span集成在一起展示,等等等等。最终,管理员可能会决定清理一些历史数据,然后我们的span就结束了整个生命循环,消失在历史长河中。
问题后续
在这之后,一起开发的同事发现了我们Jaeger Span使用中的问题,主要原因是Span创建的语句没有放到try with resource中去,导致内存中相关资源没有被回收,产生的内存泄露。截取代码如下:
原代码:
1 | ("@annotation(com.company.department.project.opentracing.Traced)") |
修改后的代码:注意其中scope放到了try with resource中去。
1 | ("@annotation(com.company.department.project.opentracing.Traced)") |